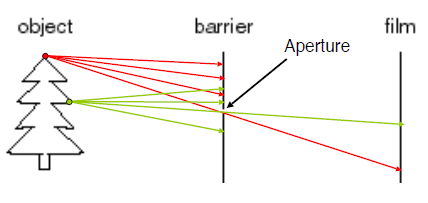
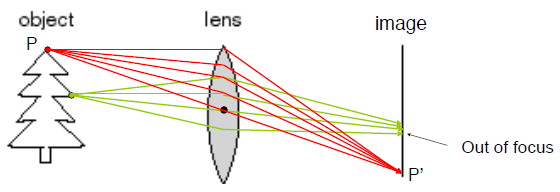
이전 핀홀 카메라 모델에서 카메라 파라미터를 구하기 위해서 카메라 캘리브레이션이라는 것을 해야한다고 했습니다. 그 카메라 캘리브레이션의 의미와 방법에 대해 조금 더 깊게 살펴볼게요.
들어가기전에 좌표계에 대해서 알아보죠. 일단 필요한 세가지 좌표계를 생각해볼 수 있습니다. 첫번째로 우리가 보는 실세계의 3차원 좌표계를 World coordinate system이라고 합니다. 그렇다면 이 Coordinate system의 기준이 되는 Origin과 서로 직교하는 3차원 축 방향을 마련해야겠죠? 이 것은 정하기 나름입니다만 보통 입력으로 들어오는 첫 프레임의 카메라 위치를 기준으로 정합니다.
그리고 두번째 좌표계는 각 프레임마다 카메라의 중심이 Origin이 되고 각 축을 만드는 Camera coordinate system이 있겠죠. 그럼 위에서 말한 것과 같이 첫 프레임은 카메라좌표계와 실세계 좌표계가 동일합니다. 그러면 두 번째 프레임 부터, 점 $P_c$을 Global coordinate로 옮길 땐 첫 프레임을 찍을 때보다 카메라가 얼만큼 움직였는지 알아내 그 만큼을 역으로 계산하면 됩니다.
마지막으로는 픽셀 좌표계입니다. 즉, 실제 World coordinate에서 Camera coordinate를 거쳐 다시 2차원 pixel로 맵핑 된 후의 좌표계입니다. 향후 SfM이나 SLAM등에서는 2차원 Pixel에서 3차원 World coordinate를 알아내는 과정을 진행함으로써 3D points cloud 혹은 volume을 생성해 냅니다.
이 좌표계 변환에서 유용하게 쓰일 뿐만아니라 이것이 전부 일 수 있는 Camera extrinsic (Rotation, Translation), Camera intrinsic을 살펴 보겠습니다.
Extrinsic은 World 좌표계에서 Camera 좌표계로 변환시키는 과정입니다. 이 때 파라미터는 Rotation(회전)과 Translation(평행이동)으로 구성되어 있습니다. 즉, 3D to 3D Rigid Transformation입니다.
$$
P_c = \begin{bmatrix}R_{3 \times 3} & T_{3 \times 1} \\ 0 & 1 \end{bmatrix}P_w
$$
반면 Intrinsic은 3D Camera coordinate에서 2D Pixel coordinate으로 Projective transformation시킨 것 입니다. 이 Transformation은 Pinhole camera model에 의해서 다음과 같은 변환관계가 있습니다.
$$
P'=\begin{bmatrix} \alpha & - \alpha cot \theta & u_o & 0 \\ 0 & \frac{\beta}{sin\theta} & v_o & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix}P_c
$$
여기서 $f$= focal length, $u_0,v_0$= offset , $\alpha, \beta \rightarrow$ non-square pixel, $\theta$=skew angle입니다. skew angle은 요즘 카메라에서 거의 일어나지 않아없다고 봐도 무방합니다.
그러므로 World-coordinate에서 Pixel-coordinate까지 최종 Transform은
$$
P' = MP_w=K\begin{bmatrix} R & T \end{bmatrix}P_w = \begin{bmatrix} \alpha & -\alpha cot\theta & u_o & 0 \\ 0 & \frac{\beta}{ sin\theta } & v_0 & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix} \begin{bmatrix}R & T \\ 0 & 1 \end{bmatrix}P_w
$$
입니다.
들어가기전에 좌표계에 대해서 알아보죠. 일단 필요한 세가지 좌표계를 생각해볼 수 있습니다. 첫번째로 우리가 보는 실세계의 3차원 좌표계를 World coordinate system이라고 합니다. 그렇다면 이 Coordinate system의 기준이 되는 Origin과 서로 직교하는 3차원 축 방향을 마련해야겠죠? 이 것은 정하기 나름입니다만 보통 입력으로 들어오는 첫 프레임의 카메라 위치를 기준으로 정합니다.
그리고 두번째 좌표계는 각 프레임마다 카메라의 중심이 Origin이 되고 각 축을 만드는 Camera coordinate system이 있겠죠. 그럼 위에서 말한 것과 같이 첫 프레임은 카메라좌표계와 실세계 좌표계가 동일합니다. 그러면 두 번째 프레임 부터, 점 $P_c$을 Global coordinate로 옮길 땐 첫 프레임을 찍을 때보다 카메라가 얼만큼 움직였는지 알아내 그 만큼을 역으로 계산하면 됩니다.
마지막으로는 픽셀 좌표계입니다. 즉, 실제 World coordinate에서 Camera coordinate를 거쳐 다시 2차원 pixel로 맵핑 된 후의 좌표계입니다. 향후 SfM이나 SLAM등에서는 2차원 Pixel에서 3차원 World coordinate를 알아내는 과정을 진행함으로써 3D points cloud 혹은 volume을 생성해 냅니다.
이 좌표계 변환에서 유용하게 쓰일 뿐만아니라 이것이 전부 일 수 있는 Camera extrinsic (Rotation, Translation), Camera intrinsic을 살펴 보겠습니다.
 |
| Camera Coordinate System (출처 : http://kr.mathworks.com/help/vision/ug/camera-calibration.html) |
$$
P_c = \begin{bmatrix}R_{3 \times 3} & T_{3 \times 1} \\ 0 & 1 \end{bmatrix}P_w
$$
반면 Intrinsic은 3D Camera coordinate에서 2D Pixel coordinate으로 Projective transformation시킨 것 입니다. 이 Transformation은 Pinhole camera model에 의해서 다음과 같은 변환관계가 있습니다.
$$
P'=\begin{bmatrix} \alpha & - \alpha cot \theta & u_o & 0 \\ 0 & \frac{\beta}{sin\theta} & v_o & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix}P_c
$$
여기서 $f$= focal length, $u_0,v_0$= offset , $\alpha, \beta \rightarrow$ non-square pixel, $\theta$=skew angle입니다. skew angle은 요즘 카메라에서 거의 일어나지 않아없다고 봐도 무방합니다.
그러므로 World-coordinate에서 Pixel-coordinate까지 최종 Transform은
$$
P' = MP_w=K\begin{bmatrix} R & T \end{bmatrix}P_w = \begin{bmatrix} \alpha & -\alpha cot\theta & u_o & 0 \\ 0 & \frac{\beta}{ sin\theta } & v_0 & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix} \begin{bmatrix}R & T \\ 0 & 1 \end{bmatrix}P_w
$$
입니다.